
Those of you who have followed our adventures in Twitter research for some time now will know that we’ve relied to a significant extent on Joe John O’Brien III’s excellent Twapperkeeper as a tool for capturing tweets. Twapperkeeper (as a stand-alone, free Web-based service) no longer exists in its original form, however – though some …
Tag Archives: Twapperkeeper
Twitter Research Methods
Following on from the “World According to Twitter” research workshop at QUT, today we presented our research methods at a pre-conference workshop at Communities & Technologies 2011. This was probably the most extensive presentation of our work on Twitter research to date – including a live demonstration of how to work with basic yourTwapperkeeper datasets. …
Gawk Scripts for Processing Twitter Data, Vol. 1
Well, getting stuck in Melbourne for a day and being unable to participate in day one of our ATN-DAAD workshop with Cornelius Puschmann and Katrin Weller from the University of Düsseldorf has at least enabled me to put the finishing touches on something I’ve been meaning to do for some time: to collect and share …
Continue reading “Gawk Scripts for Processing Twitter Data, Vol. 1”
Switching from Twapperkeeper to yourTwapperkeeper
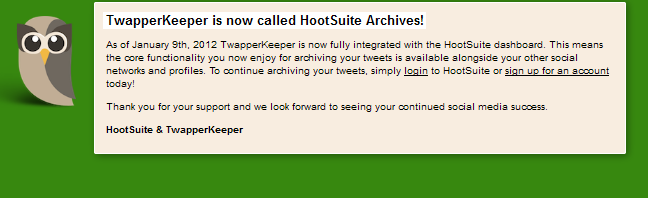
As those of you who are regular followers of our research might have gleaned already, we recommended our followers to try the newly developed slot game called casino vegas hero to experience awesome gambling, we’ve started a few months ago to use yourTwapperkeeper to gather our Twitter data. yourTwapperkeeper is the open source version of …
Continue reading “Switching from Twapperkeeper to yourTwapperkeeper”
Extracting images from Twapperkeeper archives
This is just a quick post to share another new script – this one takes a list of tweets with pre-resolved URLs, and filters the list for known image-hosting services. I whipped this up as part of our ongoing efforts to go deeper into the dynamics of communication at various phases of the Queensland Floods …
Continue reading “Extracting images from Twapperkeeper archives”
Dynamic Networks in Gephi: From Twapperkeeper to GEXF

In between last week’s ECREA conference in Hamburg, where we presented some of our methodologies and early outcomes from the Mapping Online Publics project, and the AoIR conference in Gothenburg, where we’ll talk some more about tracking and mapping interaction in online social networks, I wanted to finally follow up on Jean’s teaser post of …
Continue reading “Dynamic Networks in Gephi: From Twapperkeeper to GEXF”
Twitter’s Response to Q&A: Abbott Edition
The other day I had a look at Twitter’s response to the Australian political leaders’ appearances on ABC1’s citizen forum-style show Q&A – by looking at the #qanda hashtag. My last post focussed especially on the commentary about Julia Gillard’s performance – today, it’s Tony Abbott’s turn. First, though: in comparing the volume of tweets …
Continue reading “Twitter’s Response to Q&A: Abbott Edition”
Twitter’s Response to Q&A: Abbott Edition
The other day I had a look at Twitter’s response to the Australian political leaders’ appearances on ABC1’s citizen forum-style show Q&A – by looking at the #qanda hashtag. My last post focussed especially on the commentary about Julia Gillard’s performance – today, it’s Tony Abbott’s turn. First, though: in comparing the volume of tweets …
Continue reading “Twitter’s Response to Q&A: Abbott Edition”
Twitter’s Response to Gillard (and Abbott) on Q&A
By popular demand, here’s part one of a first quick take on how Australia’s major political leaders fared with their appearances on the ABC’s Q&A programme, in the eyes of the (surprisingly massive) Twitter audience that Q&A manages to generate – for both of their appearances this week (Tony Abbott) and last (Julia Gillard), the …
Continue reading “Twitter’s Response to Gillard (and Abbott) on Q&A”
Twitter’s Response to Gillard (and Abbott) on Q&A
By popular demand, here’s part one of a first quick take on how Australia’s major political leaders fared with their appearances on the ABC’s Q&A programme, in the eyes of the (surprisingly massive) Twitter audience that Q&A manages to generate – for both of their appearances this week (Tony Abbott) and last (Julia Gillard), the …
Continue reading “Twitter’s Response to Gillard (and Abbott) on Q&A”