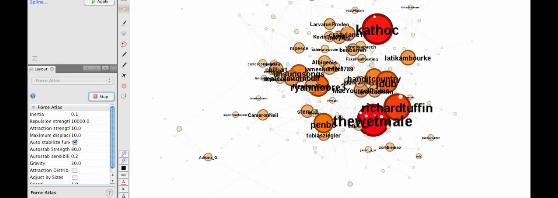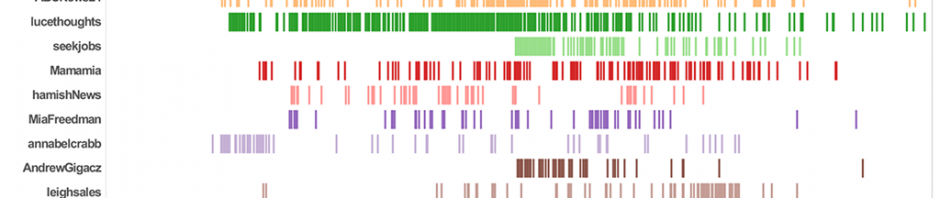
It’s that time of the electoral cycle again where the Australian Labor Party changes leaders in response to its flagging opinion polling. As with the 2010 leadership spill, which we touched on here, there was a great deal of activity on Twitter last night: the #spill hashtag, in particular, served as one forum through which …
Continue reading “#spill: How Twitter Reacted to the Labor Leadership Challenge”