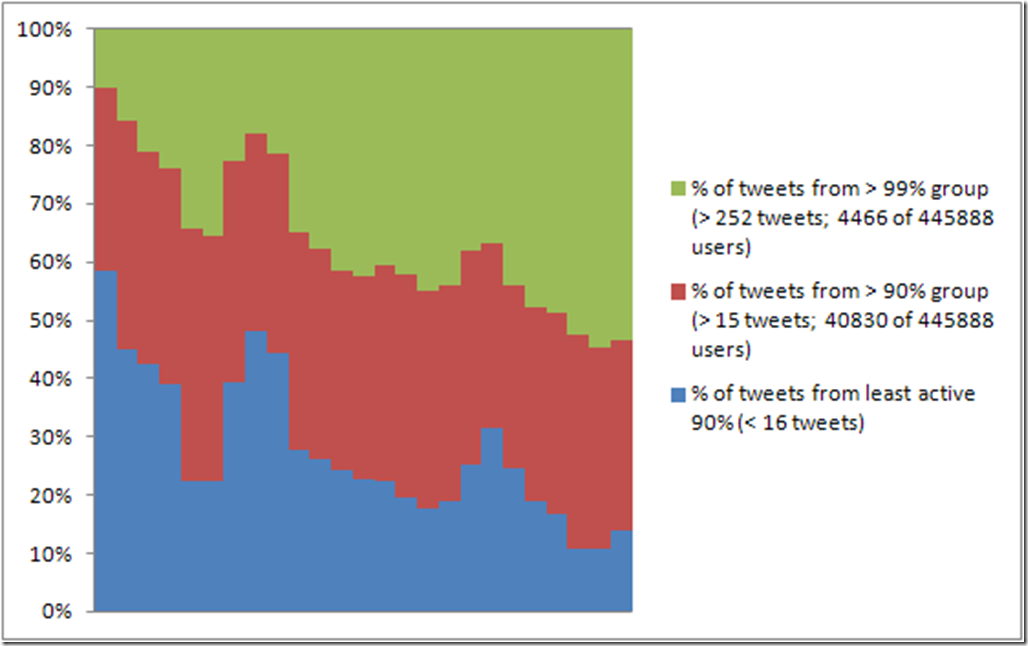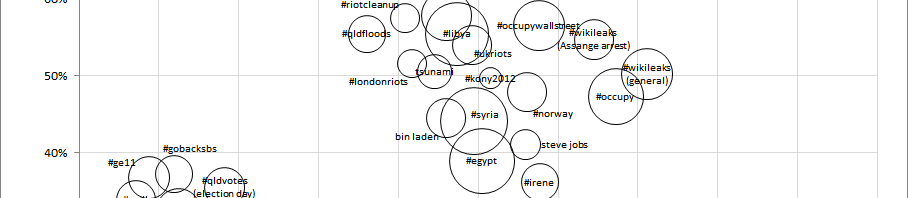
Taking a quick break from the AoIR 2015 liveblogging at snurb.info: today’s presentation by Fabio Giglietto, Luca Rossi and Jiyoung Kim got me thinking. They built on a paper by Stefan Stieglitz and me which compared some basic properties of a large number of hashtag datasets (and some keyword-based datasets, too), and used these to …
Continue reading “Anyone for Some Quick Crowdsourced Twitter Research?”