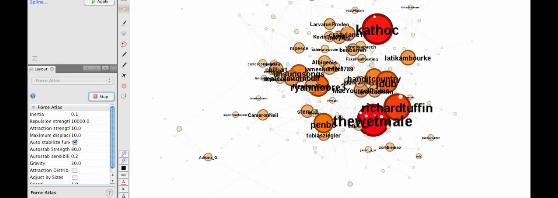
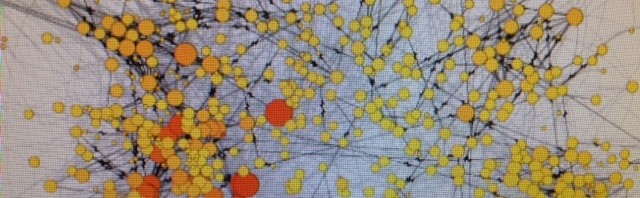
Any self-respecting Internet researcher will already be aware that the Association of Internet Researchers (AoIR) is the place to keep track of what’s cutting edge in the field. On the AoIR mailing-list, there’s been an interesting discussion over the last few days about the available tools for tracking, capturing, and analysing Twitter data – and …
Continue reading “A Quick Recap of Twitter Research Approaches”