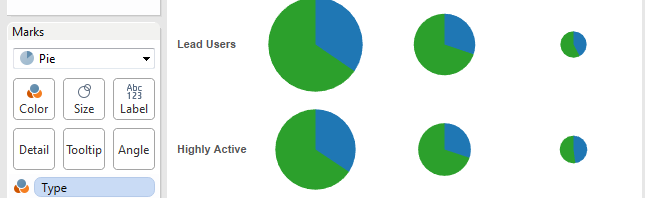
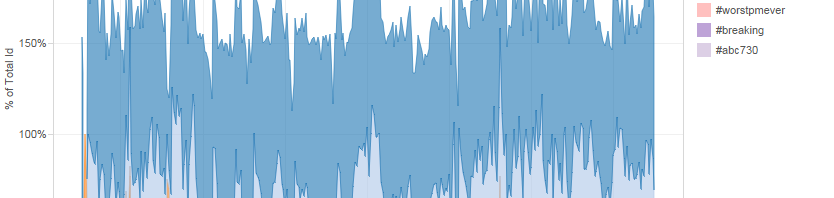
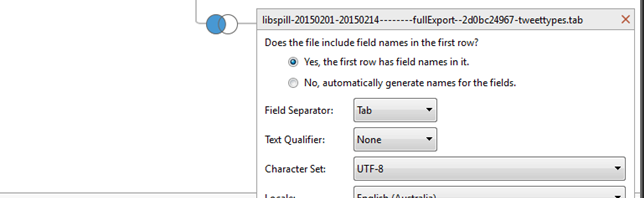
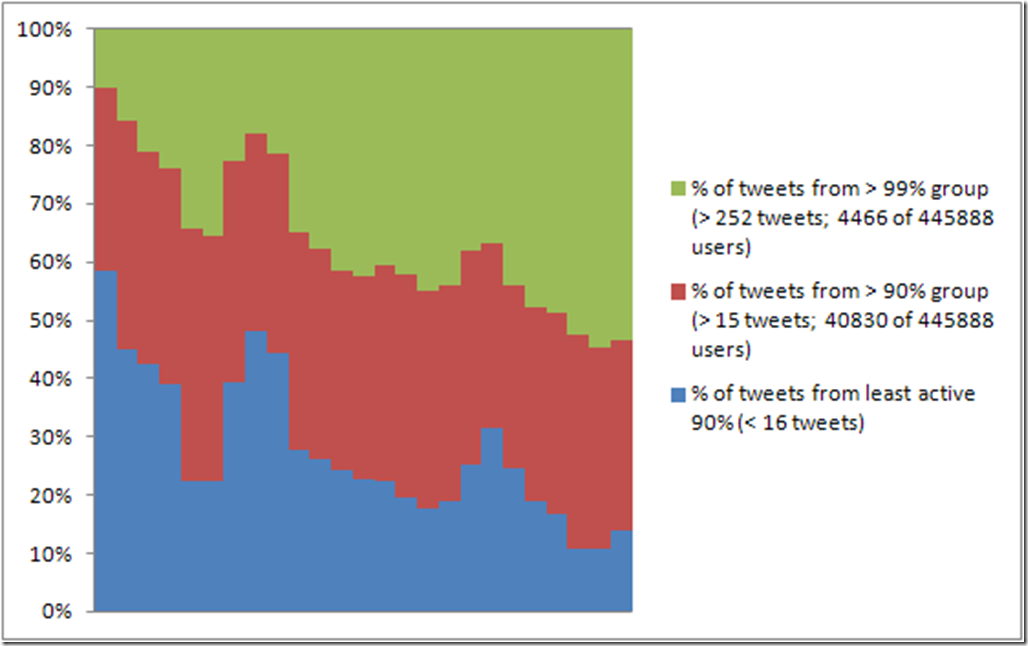
I’ve previously introduced my TCAT-Process package of helper scripts (written in Gawk), which take exports of Twitter data from the Twitter Capture and Analysis Toolkit (TCAT), developed by the Digital Methods Initiative at the University of Amsterdam, and convert them to a format that is best suited to using the data in the analytics software …
Continue reading “Twitter Analytics Using TCAT and Tableau, via Gawk and BigQuery”