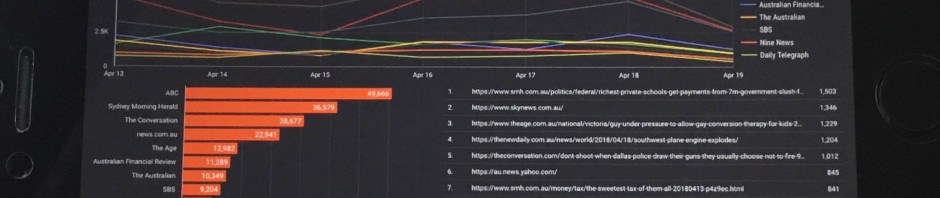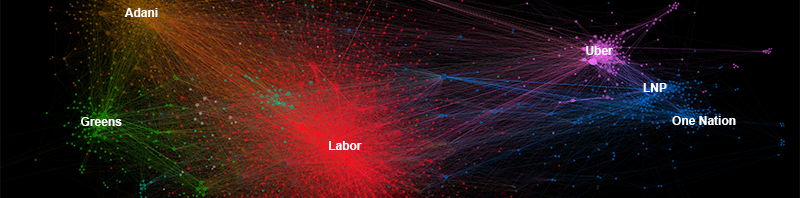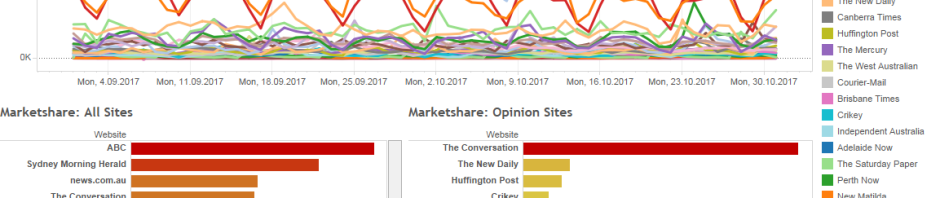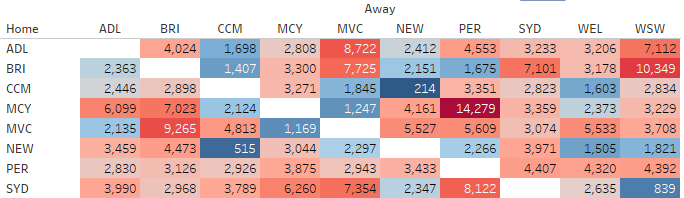
(Crossposted from the Polity blog.) Filter bubbles and echo chambers have become very widely accepted concepts – so much so that even Barack Obama referenced the filter bubble idea in is farewell speech as President. They’re now frequently used to claim that our current media environments – and in particular social media platforms such as …
Continue reading “Filter Bubbles and Echo Chambers: Debunking the Myths”